
Skoro dane już wyświetlają się na ekranie trzeba zrobić coś żeby można było je odświeżyć bez potrzeby ponownego uruchomienia aplikacji. Użyję widżetu SwipeRefreshLayout.
Continue reading „Sensorki – refresh – #2”Sensorki – widok i adapter – #1

Dane z serwera już pobrane, czas je wyświetlić. Na razie bez szaleństw – dopieszczać będziemy później 😉
Continue reading „Sensorki – widok i adapter – #1”Sensorki – aplikacja „pogodowa” – #0

Dawno temu Mąż porozstawiał po domu sensorki [specyfikacja sensorków] zbierające dane na temat m. in. temperatury i wilgotności w pomieszczeniach mieszkania i z balkonu. Do tej pory jedynym dostępem do danych jest strona internetowa. Nie może tak być – trzeba zrobić aplikację na Androida 😉
Continue reading „Sensorki – aplikacja „pogodowa” – #0″Gra w życie -> Maszyna stanów w Groovy’m
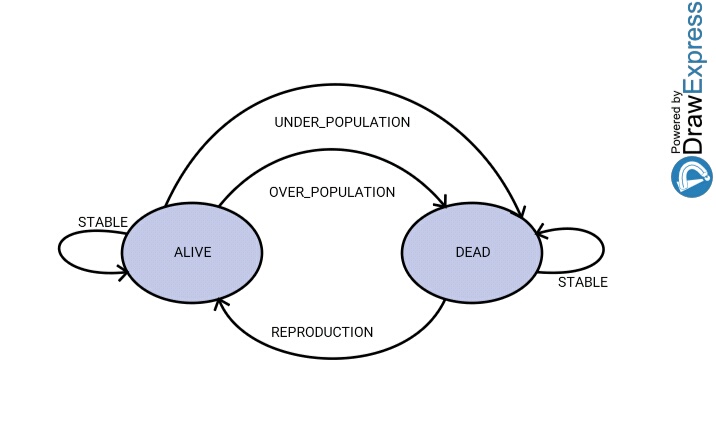
Natknęłam się ostatnio w sieci na wpis o implementacji maszyny stanów w Groovy’m i postanowiłam wykorzystać ten pomysł w praktyce. Do implementacji wybrałam Grę w Życie. Algorytm nie jest skomplikowany, każda komórka może przyjąć jeden z dwóch stanów, a i przejść między stanami nie jest za dużo. Continue reading „Gra w życie -> Maszyna stanów w Groovy’m”
Projekt Euler – zadanie 8 – Window sliding technique

Rozwiązuję sobie ostatnio zadania z Projektu Euler i natrafiłam na zadanie 8, które zainspirowało mnie do tej notki.

Największy iloczyn 13 kolejnych cyfr z 1000 cyfrowej liczby 🙂 Można to zrobić najprościej – pętla po wszystkich cyfrach, a potem branie 13 kolejnych cyfr. Wynik dla 4 kolejnych cyfr, który jest podany w treści zadania wykorzystam jako test sprawdzający.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def ex8(window_size): | |
| large_number = open("source.txt", 'r').read() | |
| max_product = 1 | |
| for i in range(0, len(large_number)): | |
| product = 1 | |
| if i + window_size <= len(large_number): | |
| for j in range(i, i + window_size): | |
| product *= int(large_number[j]) | |
| max_product = max(max_product, product) | |
| return max_product | |
| assert ex8(4) == 5832 | |
| print(ex8(13)) |
Niestety, nie optymalne, złożoność czasowa aż O(n*k). Dla 4 liczb mamy 4 * 1000 obrotów w pętli, ale dla 13 to już 13000. A gdyby liczba była 10, 100 razy większa? Musi być inny sposób… I jest.
Window sliding technique – technika przesuwanego okienka. Można to sobie wyobrazić jako kalendarz z przesuwanym na taśmie okienkiem:

Dla uproszczenia skupię się na mniejszym przykładzie i poszukam największej sumy z wymyślonej mniejszej liczby. W tym wypadku okienko będzie mieściło w sobie 4 cyfry.
Algorytm wygląda tak:
- Wyliczamy początkową sumę w okienku (window_sum) – jest ona w tym momencie również maksymalną sumą (max_sum)
- Przesuwamy okienko – wyliczamy kolejną sumę korzystając z poprzednich wyliczeń:
- od window_sum odejmujemy cyfrę, która opuściła okienko
- do window_sum dodajemy cyfrę, która trafiła do okieka
- Jeśli nowa suma jest większa niż max_sum, to za max_sum przypisujemy window_sum
- Jeśli mamy jeszcze jakieś cyfry w „dużej liczbie” to wracamy do punktu 2
W formie graficznej wygląda to mniej więcej tak:



A kod tak:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| large_number = '6717483933' | |
| large_number_array = list(map(int, large_number)) | |
| def count_max_sum(window_size): | |
| if len(large_number) < window_size: | |
| return -1 | |
| max_sum = 0 | |
| for i in range(0, window_size): | |
| max_sum += large_number_array[i] | |
| window_sum = max_sum | |
| for i in range(window_size, len(large_number_array)): | |
| window_sum += large_number_array[i] – large_number_array[i – window_size] | |
| max_sum = max(max_sum, window_sum) | |
| return max_sum | |
| print(count_max_sum(4)) |
Tutaj kroków w pętli jest tyle ile wynosi długość „dużej liczby”, czyli złożoność czasowa O(n). Zupełnie nie zależy to od wielkości okienka.
Ok, ale to było dodawanie, a w zadaniu każą znaleźć największy iloczyn.
Niestety nie można po prostu przenieść wersji z dodawaniem na mnożenie:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| large_number = open("source.txt", 'r').read() | |
| large_number_array = list(map(int, str(large_number))) | |
| def find_max_product(k): | |
| max_product = 1 | |
| for i in range(0, k): | |
| max_product *= large_number_array[i] | |
| window_product = max_product | |
| for i in range(k, len(large_number_array)): | |
| window_product = window_product // large_number_array[i – k] * large_number_array[i] | |
| max_product = max(window_product, max_product) | |
| return max_product | |
| assert find_max_product(4) == 5832 | |
| print(find_max_product(13)) |
Bardzo szybko wypadnie error, że nie wolno dzielić przez 0.
Pierwsze zabezpieczenie: sprawdźmy, czy następny element jest równy 0. Jeśli jest to przeskakujemy go i wyliczamy od nowa sumę w okienku.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| (…) | |
| if next_item is not 0: | |
| window_product = window_product // previous_item * next_item | |
| i += 1 | |
| else: | |
| i += 1 | |
| window_product = 1 | |
| if i + k <= len(large_number_array): | |
| for j in range(i, i + k): | |
| window_product *= large_number_array[j] | |
| else: | |
| break | |
| i += k | |
| (…) |
Prawie dobrze, ale co w wypadku jeśli w nowym okienku znajdzie się 0, a może nawet dwa, więc omińmy je wszystkie:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| (…) | |
| while 0 in large_number_array[i:i + k]: | |
| zero_index = large_number_array[i:i + k].index(0) | |
| i += zero_index + 1 | |
| (…) |
Można by się jeszcze pokusić o sprawdzanie, czy w pierwszym okienku jest 0 i trochę refaktoringu. Finalnie program wygląda tak:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| large_number = open("source.txt", 'r').read() | |
| large_number_array = list(map(int, large_number)) | |
| def find_max_product(window_size): | |
| if len(large_number_array) < window_size: | |
| return -1 | |
| i = skip_zeros(0, window_size) | |
| max_product = count_initial_product(i, window_size) | |
| i += window_size | |
| window_product = max_product | |
| while i + window_size <= len(large_number_array): | |
| next_item = large_number_array[i] | |
| previous_item = large_number_array[i – window_size] | |
| if next_item is not 0: | |
| window_product = window_product // previous_item * next_item | |
| i += 1 | |
| else: | |
| i = skip_zeros(i, window_size) | |
| if i + window_size <= len(large_number_array): | |
| window_product = count_initial_product(i, window_size) | |
| else: | |
| break | |
| i += window_size | |
| max_product = max(window_product, max_product) | |
| return max_product | |
| def skip_zeros(i, window_size): | |
| while 0 in large_number_array[i:i + window_size]: | |
| zero_index = large_number_array[i:i + window_size].index(0) | |
| i += zero_index + 1 | |
| return i | |
| def count_initial_product(i, window_size): | |
| window_product = 1 | |
| for j in range(i, i + window_size): | |
| window_product *= large_number_array[j] | |
| return window_product | |
| assert find_max_product(4) == 5832 | |
| print(find_max_product(13)) |
Więcej zadań, które można rozwiązać przy pomocy tej techniki można znaleźć tu: https://www.geeksforgeeks.org/tag/sliding-window/
Gradle na Heroku
Notatka na przyszłość – tak ma wyglądać Procfile jak robisz deploy aplikacji napisanej w Javie na Heroku i korzystasz z gradle’a:
Continue reading „Gradle na Heroku”Nanodegree – kolejna faza
Blog leży odłogiem, bo dostałam się na kolejny etap kursu Android Udacity Nanodegree. Dodatkowo praca + zwykłe choroby żłobkowego dziecka sprawiają, że mało jest czasu na cokolwiek dodatkowego. Ale na rocznice założenia bloga postanowiłam zainwestować w niego trochę i wykupiłam własny hosting i podpięłam go pod domenę zastępując moją małą statyczną wizytówkę. Będę musiała się trochę odnaleźć w tej przestrzeni jaką daje mi własny wordpress. W końcu będę miała dostęp do google analytics 🙂
Jak na razie w ramach Nanodegree zrobiłam dwa projekty:
- Sandwich club – w sumie polegało to na tym żeby uzupełnić brakującą część kodu odpowiadającą za parsowanie jsona i stworzyć mały layout pokazujący szczegóły wybranej kanapki. Ten projekt służył bardziej temu żeby odnaleźć się w systemie pracy z review i wdrażaniem feedbacku. https://github.com/jezinka/sandwich-club
- Popular Movies Stage 1 – tu już można było bardziej poszaleć. Zadanie polegało na wykonaniu aplikacji, która komunikuje się z API themoviedb.org i prezentuje wyniki. W przeciwieństwie do poprzedniego zadania, to trzeba było zrobić od podstaw. https://github.com/jezinka/PopularMovies/tree/stage_1
Teraz przede mną zrobienie bardziej skomplikowanej wersji drugiego projektu. Poza odtwarzaniem trailerów w zewnętrznej aplikacji czeka mnie zrobienie bazy danych i content providera. Mam na to jeszcze cały miesiąc.
Jak zostać Panią Swojego Czasu? – #książka
Mikołaj pod choinkę przyniósł mi książkę Oli Budzyńskiej „Jak zostać Panią Swojego Czasu”. Jestem już po lekturze, więc czemu nie napisać kilku słów na bloga.
Continue reading „Jak zostać Panią Swojego Czasu? – #książka”
Odjazd – rasowy klient – #03
Przerwa międzyświąteczna sprzyja powstawaniu kodu. Udało mi się zamienić prowizorycznego klienta na takiego bardziej profesjonalnego. Continue reading „Odjazd – rasowy klient – #03”
Odjazd – prowizoryczny klient – #02
Mam już działający serwer, który potrafi wysłać jsona w świat. Trzeba mi teraz czegoś co odbierze tego jsona i wyświetli użytkownikowi. Czas na prowizorycznego klienta. Choć to prowizorka, to powinien naprawdę komunikować się z serwerem, a nie tylko to udawać. Continue reading „Odjazd – prowizoryczny klient – #02”